متا از مدل هوش مصنوعی مولد Voicebox معرفی کرد
متا به تازگی جدیدترین مدل هوش مصنوعی مولد خود را به نام ImageBind Voicebox معرفی کرده، که برای کمک به سازندگان با توانایی خود در انجام وظایف تولید گفتار مانند ویرایش صدا، نمونهبرداری و سبکسازی طراحی شده است، حتی اگر به طور خاص اینطور نبوده باشد. برای انجام این کار از طریق یادگیری درون متنی آموزش دیده اند.
متا ادعا می کند که این مدل جدید هوش مصنوعی برای بسیاری از افراد در سراسر جهان مزایایی خواهد داشت و از مثال هایی مانند کمک به افراد کم بینا برای شنیدن پیام های مکتوب دوستان در صدای خود و همچنین اجازه دادن به افراد برای صحبت به زبان های خارجی با صدای خود استفاده می کند.
خود مدل هوش مصنوعی می تواند هم کلیپ های صوتی با کیفیت بالا تولید کند و هم صدای از پیش ضبط شده را ویرایش کند تا اختلالات ناخواسته مانند بوق ماشین را حذف کند و در عین حال محتوا و سبک صدا را حفظ کند و در عین حال چند زبانه باشد و گفتار به شش زبان تولید کند. پیشرفتهای آینده این مدل شامل دادن صداهایی با صدای طبیعی به دستیاران بصری یا شخصیتهای غیربازیکن در طول بازی در متاورس است.
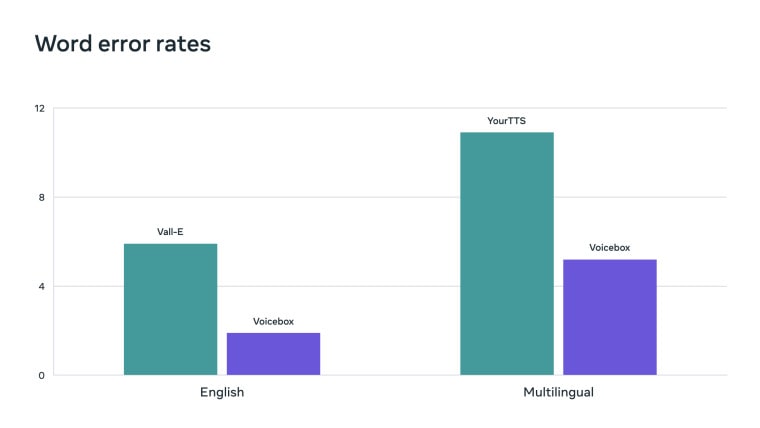
متا همچنین Voicebox را با سایر مدلهای هوش مصنوعی صوتی موجود مقایسه کرده است، به طور خاص از Vall-E و YourTTS به عنوان رقبا نام برده است، و نشان میدهد که Voicebox پیشرفتهتر است و در مقایسه میزان خطای Word و شباهت سبک، از هر دو مدل برتری دارد. Voicebox بر اساس یک مدل Flow Matching ساخته شده، که جدیدترین مدل تولیدی متا است که میتواند نگاشت بسیار غیر قطعی بین متن و گفتار را بیاموزد، و Voicebox را قادر میسازد تا از دادههای گفتاری متنوع بیاموزد بدون اینکه نیازی به برچسبگذاری دقیق باشد. داده ها متنوع تر و در مقیاس بزرگتر باشند.
Voicebox تاکنون بر روی بیش از 50000 ساعت گفتار ضبط شده و رونوشت از کتابهای صوتی با مالکیت عمومی به زبانهای انگلیسی، فرانسوی، اسپانیایی، آلمانی، لهستانی و پرتغالی آموزش دیده و همچنین میتواند یک بخش گفتار را با توجه به گفتار اطراف و رونوشت پیشبینی کند. در نهایت، متا ادامه داد که اگرچه این فناوری می تواند عصر جدیدی از هوش مصنوعی مولد برای گفتار به ارمغان بیاورد، می تواند احتمال سوء استفاده و آسیب های ناخواسته را به همراه داشته باشد.