دستیبابی عملکرد پیشرفته مدل Qwen2-VL علی بابا در چندین بنچمارک هوش مصنوعی
علی بابا اعلام کرده است که مدلهای زبان بینایی از خانواده Qwen2-VL، که بر اساس Qwen-2 توسعه یافتهاند، را عرضه کرده است. خانواده Qwen2-VL شامل سه مدل Qwen2-VL-72B، Qwen2-VL-2B و Qwen2-VL-7B میباشد. مدلهای Qwen2-VL-2B و Qwen2-VL-7B تحت لیسانس آپاچی 2.0 منتشر شدهاند. قویترین مدل، Qwen2-VL-72B، از طریق API رسمی در دسترس است.
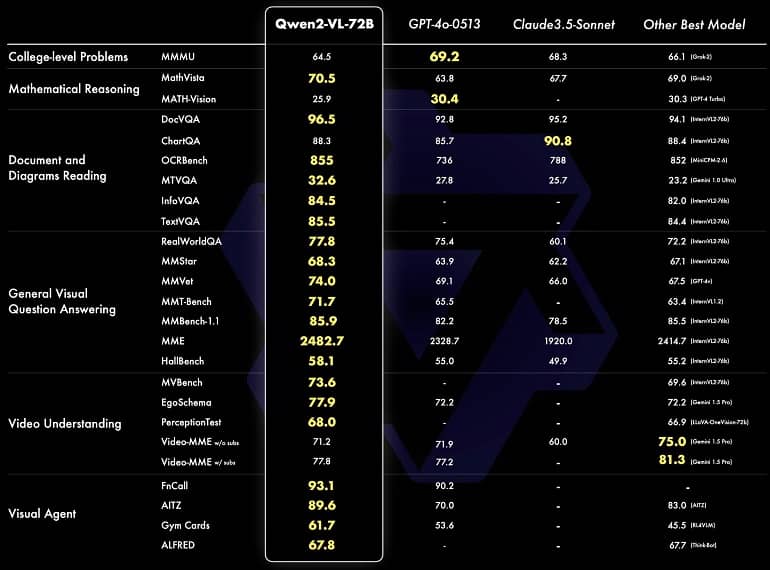
علیبابا مدعی است که مدل Qwen2-VL-72B در چندین معیار درک بصری، از جمله MathVista، DocVQA، RealWorldQA و MTVQA، به عملکرد پیشرفتهای دست یافته است. همانطور که در جدول زیر میبینید، Qwen2-VL-72B در بیشتر معیارها از OpenAI GPT-4o-0513 و Ghazal Cloud 3.5 پیشی گرفته و در بسیاری از معیارها به عملکرد برجستهای رسیده است. این نخستین بار است که یک مدل منبع باز به چنین شاخصهای معیاری دست مییابد که حتی از نمونههای منبع بسته نیز بهتر است.
علیبابا ادعا میکند که مدل Qwen2-VL قادر است ویدیوهایی با طول بیش از 20 دقیقه را درک کرده و پاسخهای مبتنی بر ویدئو با کیفیت بالا ارائه دهد. این مدل که از استدلال و تصمیمگیری پیچیده پشتیبانی میکند، قابلیت ادغام در طیف وسیعی از برنامههای کاربردی هوش مصنوعی را دارد. علاوه بر زبانهای انگلیسی و چینی، Qwen2-VL اکنون از بیشتر زبانهای اروپایی، ژاپنی، کرهای، عربی و ویتنامی پشتیبانی میکند، که آن را برای سناریوهای چندزبانه مناسب ساخته است.
مدل کوچکتر Qwen2-VL-7B، در اکثر معیارها، مدل مینی OpenAI GPT-4o را پشت سر گذاشته است. این مدل 7 بیلیون پارامتری نیز از ورودیهای تصویری، چند تصویری و ویدئویی پشتیبانی میکند. بر اساس معیارها، مدل Qwen2-VL-7B در وظایف درک متون و اسناد مانند DocVQA و MTVQA عملکرد بهتری نشان داده است. کوچکترین مدل Qwen2-VL-2B برای استفاده در گوشیهای هوشمند طراحی شده و در تصویربرداری، ویدئو و درک چندزبانه عملکرد قویای ارائه میدهد.
مدلهای منبع باز Qwen2-VL-7B و Qwen2-VL-2B با چارچوبهای Hugging Face Transformers، vLLM و دیگر چارچوبهای شخص ثالث ادغام شدهاند. با عملکرد برجسته و دسترسی به منبع باز، خانواده Qwen2-VL پتانسیل چشمگیری برای پیشرفت در تحقیق و توسعه در زمینه مدلهای زبان بینایی دارد و امکان پیادهسازی برنامههای هوش مصنوعی نوآورانه در حوزههای متنوع را فراهم میآورد.