DeepSeek V3 استاندارد جدیدی را برای مدل های زبان منبع باز تنظیم می کند
DeepSeek AI، یک آزمایشگاه تحقیقاتی در چین، اخیراً مدل جدیدی به نام DeepSeek-V3 را معرفی کرده که در دنیای هوش مصنوعی منبع باز سر و صدا به پا کرده است. این مدل یک زبان بزرگ با 671 میلیارد پارامتر است و به نوعی از ترکیب متخصصان استفاده میکند. هر توکن فعال شده در این مدل 37 میلیارد پارامتر دارد. بر اساس نتایج بنچمارکهای مختلف، DeepSeek-V3 قویترین مدل منبع باز موجود به شمار میرود و عملکردش حتی از مدلهای معروف و بستهای مثل GPT-4 OpenAI و Claude 3.5 از Anthropic بهتر است.
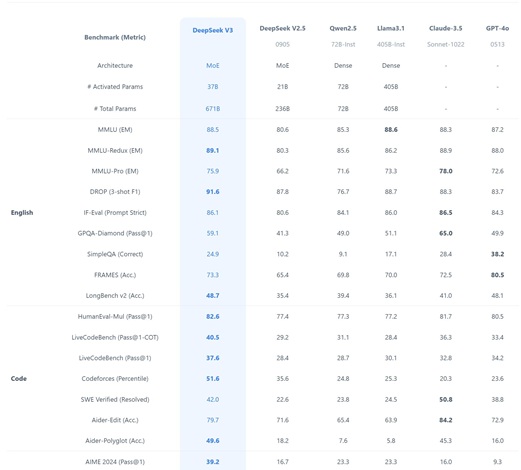
این مدل در 9 بنچمارک مختلف نتایج بسیار خوبی را کسب کرده که نشان میدهد در مقایسه با سایر مدلها در همین اندازه، بهترین عملکرد را دارد. جالب است بدانید که برای آموزش کامل DeepSeek-V3 تنها به 2.788 میلیون ساعت GPU H800 و حدود 5.6 میلیون دلار هزینه نیاز دارد. در حالی که مدل معادل منبع باز Llama 3 405B به 30.8 میلیون ساعت GPU احتیاج دارد. بهینهسازیهای عمیق و پشتیبانی از آموزش FP8 باعث شده که DeepSeek-V3 به صرفهتر باشد.
از نظر هزینه استنتاج هم، DeepSeek-V3 بسیار رقابتی است. از 8 فوریه، هزینه ورودی این مدل برای هر میلیون توکن 0.27 دلار است و خروجی آن 1.10 دلار برای هر میلیون توکن هزینه دارد. این قیمت به مراتب کمتر از هزینههایی است که شرکتهای بزرگ هوش مصنوعی مانند OpenAI برای مدلهای پیشرفته خود دریافت میکنند. در واقع، DeepSeek-V3 با این عملکرد و قیمت مناسب، میتواند گزینه جذابی برای توسعهدهندگان و محققان باشد. تیم DeepSeek اعلام میکند:
ماموریت ما همچنان قوی و ثابت قدم است. خوشحالیم که پیشرفتهای خود را با شما به اشتراک میگذاریم و میبینیم که فاصله بین مدلهای هوش مصنوعی باز و بسته کمتر و کمتر میشود. این فقط آغاز کار ماست و به زودی ویژگیهای بیشتری را در اکوسیستم DeepSeek خواهید دید.
شما میتوانید مدل DeepSeek-V3 را از GitHub و HuggingFace دانلود کنید. این نسخه با عملکرد عالی و هزینههای مناسب میتواند دسترسی به مدلهای پیشرفته هوش مصنوعی را برای همه فراهم کند. ما این نسخه را یک قدم بزرگ در راستای کاهش فاصله میان مدلهای باز و بسته میدانیم و امیدواریم که با حمایت شما، به موفقیتهای بیشتری دست پیدا کنیم.