معرفی AMD GAIA: پروژه منبع باز که LLMهای محلی را روی Ryzen AI اجرا می کند
AMD پروژهای متنباز جدید به نام GAIA (گایا) راهاندازی کرده است؛ برنامهای جذاب که از قدرت واحد پردازش عصبی (NPU) رایزن AI بهره میبرد تا مدلهای زبانی بزرگ (LLMs) را به صورت خصوصی و محلی اجرا کند. در ادامه، به ویژگیها و مزایای GAIA خواهیم پرداخت و همچنین توضیح میدهیم چگونه میتوانید از این پروژه متنباز استفاده کرده و آن را در برنامههای خود به کار بگیرید.
معرفی GAIA
GAIA یک برنامه هوش مصنوعی مولد است که برای اجرای مدلهای زبانی بزرگ (LLMs) به صورت خصوصی و محلی بر روی کامپیوترهای ویندوزی طراحی شده و برای سختافزار AMD Ryzen AI (پردازندههای سری 300 Ryzen AI) بهینهسازی شده است. این یکپارچگی امکان پردازش سریعتر و کارآمدتر را فراهم میکند (با مصرف انرژی کمتر) در حالی که دادههای شما به صورت محلی و امن نگهداری میشوند.
روی کامپیوترهای مبتنی بر Ryzen AI، گایا از طریق واحد پردازش عصبی (NPU) و پردازنده گرافیکی یکپارچه (iGPU) برای اجرای یکپارچه مدلها استفاده میکند، که از کیت توسعه نرمافزاری متنباز Lemonade (LLM-Aid) از ONNX TurnkeyML برای استنتاج مدلهای زبانی بهره میبرد. GAIA از مجموعه متنوعی از مدلهای زبانی محلی که برای اجرا روی Ryzen AI بهینه شدهاند، پشتیبانی میکند. مدلهای محبوبی مانند مشتقات Llama و Phi را میتوان برای موارد استفاده مختلف مانند پرسش و پاسخ، خلاصهسازی و وظایف پیچیده استدلال تنظیم کرد.
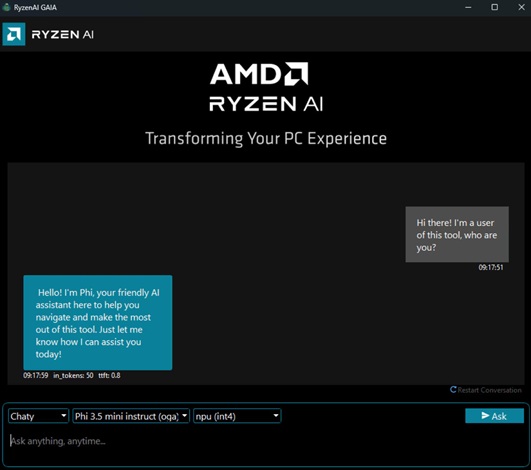
شروع کار با GAIA
برای شروع کار با GAIA در کمتر از 10 دقیقه، دستورالعملها را برای دانلود و نصب GAIA روی کامپیوتر دارای Ryzen AI دنبال کنید. پس از نصب، میتوانید برنامه GAIA را اجرا کرده و قابلیتها و عوامل متنوع آن را بررسی کنید. دو نسخه از گایا موجود است:
- GAIA Installer: این نسخه بر روی هر کامپیوتر ویندوزی اجرا میشود، اما ممکن است عملکرد آن کندتر باشد.
- GAIA Hybrid Installer: این بسته برای رایانههای دارای Ryzen AI بهینه شده و از NPU و iGPU برای ارائه عملکرد بهتر استفاده میکند.
Agent RAG Pipeline در GAIA
یکی از ویژگیهای برجسته GAIA، پایپلاین تولید بازیابیمحور (Retrieval-Augmented Generation – RAG) ایجنت آن است. این پایپلاین یک مدل زبانی بزرگ (LLM) را با یک پایگاه دانش ترکیب میکند، که به ایجنت امکان میدهد اطلاعات مرتبط را بازیابی کند، دلیلآوری کند، برنامهریزی نماید و از ابزارهای خارجی در محیط چت تعاملی استفاده کند. نتیجه این ترکیب، پاسخهایی دقیقتر و با آگاهی بیشتر از زمینه و بافت سؤال است.
ایجنت های موجود در گایا این تواناییها را ارائه میدهند:
- Simple Prompt Completion: ابزاری ساده برای تعامل مستقیم با مدل، جهت تست و ارزیابی بدون استفاده از ایجنت
- Chaty: یک ربات گفتگو (چتبات) مبتنی بر مدل زبانی بزرگ (LLM) که با تاریخچه مکالمات، تعامل کاربر را مدیریت میکند
- Clip: ایجنت RAG برای جستجو در یوتیوب و پاسخگویی به پرسشها
- Joker: یک تولیدکننده جوک ساده که با استفاده از RAG، حس شوخطبعی را به کاربران ارائه میکند
عوامل بیشتری در حال توسعه هستند، و توسعهدهندگان تشویق میشوند که عاملهای خود را ایجاد کرده و به پروژه گایا اضافه کنند.
نحوه عملکرد GAIA
در سمت چپ شکل 2 (نمودار کلی GAIA)، عملکرد کیت توسعه نرمافزاری “Lemonade” از TurnkeyML نمایش داده شده است. این کیت ابزارهایی برای وظایف مرتبط با مدلهای زبانی بزرگ (LLM) ارائه میدهد؛ از جمله تولید درخواستها، اندازهگیری دقت و سرویسدهی در بین چندین محیط اجرایی (مانند Hugging Face، ONNX Runtime GenAI API) و سختافزارهای مختلف مانند پردازنده مرکزی (CPU)، پردازنده گرافیکی یکپارچه (iGPU) و واحد پردازش عصبی (NPU).
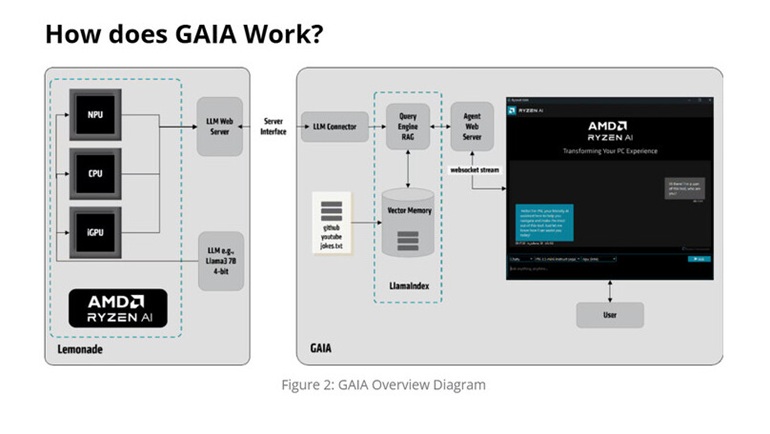
Lemonade یک سرویس وب برای مدلهای زبانی بزرگ (LLM) ارائه میدهد که از طریق API سازگار با OpenAI با برنامه گایا ارتباط برقرار میکند. گایا از سه کامپوننت اصلی تشکیل شده است:
- LLM Connector: پیوندی بین API وب سرویس NPU و پایپلاین RAG مبتنی بر LlamaIndex ایجاد میکند.
- LlamaIndex RAG Pipeline: شامل یک موتور پرسش و حافظه برداری است که اطلاعات خارجی مرتبط را پردازش و ذخیره میکند.
- Agent Web Server: از طریق WebSocket به GAIA UI متصل میشود و تعامل کاربر را ممکن میسازد.
در سمت راست نمودار، GAIA بهعنوان یک ایجنت مبتنی بر هوش مصنوعی عمل کرده و دادهها را بازیابی و پردازش میکند. این برنامه محتوای خارجی (مانند گیت هاب، یوتیوب و فایلهای متنی) را به قالب وکتور تبدیل کرده و در یک ایندکس وکتور محلی ذخیره میکند. هنگامی که کاربر یک پرسش ارسال میکند، فرآیند زیر رخ میدهد:
- پرسش به GAIA ارسال و به یک وکتور جاسازی تبدیل میشود.
- پرسش وکتور شده برای بازیابی زمینههای مرتبط از دادههای ایندکس استفاده میشود.
- زمینه بازیابیشده به سرویس وب ارسال میشود و در درخواست مدل زبانی جاسازی میشود.
- مدل زبانی پاسخ تولید میکند، که از طریق سرویس وب GAIA به صورت جریان بازگشت داده شده و در رابط کاربری نمایش داده میشود.
این فرآیند تضمین میکند که پرسشهای کاربر با زمینههای مرتبط تقویت شده و سپس توسط مدل زبانی پردازش میشوند، که دقت و مرتبط بودن پاسخها را بهبود میبخشد. پاسخ نهایی به صورت بلادرنگ از طریق رابط کاربری به کاربر ارائه میشود.
مزایای اجرای مدلهای زبانی بزرگ (LLMs) به صورت محلی
اجرای مدلهای زبانی بزرگ به صورت محلی بر روی واحد پردازش عصبی (NPU) چندین مزیت ارائه میدهد:
- حریم خصوصی بهبود یافته: دادهها از دستگاه شما خارج نمیشوند، که این امر نیاز به ارسال اطلاعات حساس به فضای ابری را از بین برده و به طور قابل توجهی امنیت و حریم خصوصی دادهها را افزایش میدهد، در حالی که همچنان قابلیتهای هوش مصنوعی با عملکرد بالا ارائه میشود.
- کاهش تأخیر: به دلیل عدم نیاز به ارتباط با فضای ابری، تأخیر به حداقل میرسد.
- عملکرد بهینهشده: استفاده از NPU منجر به زمان پاسخدهی سریعتر و کاهش مصرف انرژی میشود.
مقایسه NPU و iGPU
اجرای GAIA بر روی NPU منجر به عملکرد بهبود یافته برای وظایف خاص هوش مصنوعی میشود، زیرا برای بار کاری مرتبط با استنتاج طراحی شده است. با شروع از نسخه نرمافزار Ryzen AI 1.3، پشتیبانی ترکیبی برای استقرار مدلهای زبانی بزرگ کوانتیزهشده (quantized LLMs) ارائه شده که از هر دو NPU و iGPU استفاده میکنند. استفاده از این دو کامپوننت به صورت ترکیبی امکان بهینهسازی عملکرد برای وظایف و عملیات خاصی که هر کدام برای آن طراحی شدهاند را فراهم میکند.
کاربردها و صنایع
این ساختار میتواند برای صنایعی که به عملکرد بالا و حفظ حریم خصوصی نیاز دارند، مانند بهداشت و درمان، امور مالی و برنامههای شرکتی که حفظ حریم خصوصی دادهها در آنها حیاتی است، مفید باشد. همچنین میتوان آن را در زمینههایی مانند تولید محتوا و خودکارسازی خدمات مشتری که مدلهای هوش مصنوعی مولد در آنها ضروری شدهاند، به کار گرفت. در نهایت، این ساختار به صنایعی که دسترسی به وایفای برای ارسال دادهها به فضای ابری ندارند نیز کمک میکند، زیرا تمام پردازش به صورت محلی انجام میشود.